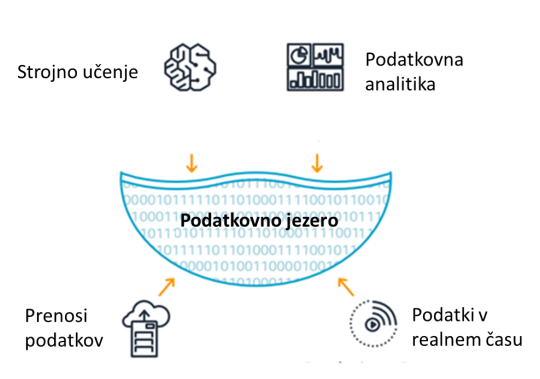
Srečamo
se s pojmom podatkovnih jezer (data lakes).
Podatkovno jezero je
centralizirano skladišče podatkov, ki so shranjeni v surovi
(naravni) obliki.
Vsebuje kopije surovih podatkov (iz senzorjev, družbenih medijev ipd)
pa
tudi predelane podatke, kot so poročila, vizualizacije, podatki iz
napredne analitike in strojnega učenja.
Podatkovno jezero lahko
vključuje tako strukturirane podatke iz relacijskih baz (tabele), kot
tudi delno strukturirane podatke (CSV, XML, JSON) in povsem
nestrukturirane
podatke (elektronska pošta, dokumenti, pdf) ter binarne podatke (slike,
avdio, video).
Medtem ko klasično hierarhično podatkovno skladišče shranjuje podatke v
datotekah ali mapah, shranjuje podatkovno jezero podatke
brez hierarhije. Vsakemu podatkovnemu elementu v jezeru je dodeljen
edinstven identifikator in je označen z nizom metapodatkov. Ko želimo
odgovor na neko vprašanje, lahko s poizvedbo v
podatkovnem jezeru poiščemo ustrezne podatke, nato pa tako pridobljeni
ožji izbor podatkov podrobneje analiziramo.
Kot primer omenimo Hadoop. To
je je odprtokodni okvir, ki temelji na Javi in se uporablja za
shranjevanje in obdelavo velikih podatkov. Podatki so shranjeni na
poceni strežnikih, ki delujejo kot grozdi. Njegov porazdeljeni
datotečni sistem omogoča sočasno obdelavo in odpornost na napake.
|
|